Five myths and misconceptions about Candid’s grant data

At Candid, our mission is to get you the information you need to do good. This also means clearing up misinformation when we come across it. In service of this, in this blog, we’re highlighting five things we’ve heard about our grants data that aren’t quite accurate.
Myth 1: “Candid grants data” is the same as “990 data.”
U.S. tax exempt nonprofit organizations must file various Forms 990 with the Internal Revenue Service (IRS) each year. These forms are a primary source of data about U.S. institutional grantmaking and provide the starting place and scaffolding for Candid’s grants data. However, “Candid grants data” and “990 data” are far from synonymous. In addition to 990s, Candid includes two additional primary data sources:
Funder contributed data. Hundreds of funders share grantmaking data directly with Candid. This data is usually more recent than data received from the IRS. Many of the largest U.S. foundations (e.g. Bill & Melinda Gates Foundation, Ford Foundation, and Hewlett Foundation) share such data with Candid.
Other public information. Candid staff also scan websites, press releases, social media, and news sources for grantmaking information. When applicable, this information is included in Candid’s data sets. These searches tend to focus on narrow, high-profile issues, such as Covid-19 or racial equity. This data source makes up a small percentage of our data but offers early insights and signals about the latest giving on critical topics.
Once Candid collects data from these sources, we clean, code, structure, and enhance the data to make it more accessible and useful. For example, we correct errors in addresses, add geographic coding, and map pieces of information into a standardized format. We also link grants from different funders to the same recipient to visualize the broader funding ecosystem. Finally, we add Candid’s Philanthropy Classification System (PCS), a comprehensive coding system that allows people to sort grants by hundreds of categories to better understand where funding is going and what it’s for.
Myth 2: Candid’s newer data is 100% web-scraped and auto-coded.
Candid has been a pioneer of using AI and machine learning to scale up the amount of data we can process. However, these methods are used to enhance other data sources and methods, not completely replace them. In fact, only a small number of grants are web-scraped from other public sources. The primary reason we web-scrape data is to find early signals of giving trends before 990s are released to fill in the details. The chart below shows how the percentage of our data sources shift as more 990 data comes in.
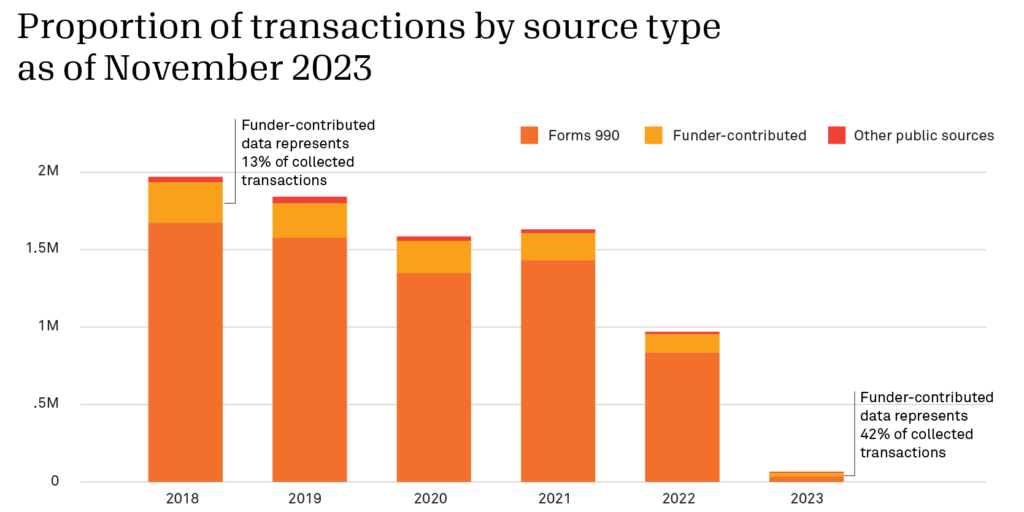
Additionally, while our AI auto-coding algorithms offer a first pass at coding the data (something that is necessary due to the vast amounts of data that filter through our systems), we still manually review many large grants, especially those included in the Foundation 1000 set, as we know that these grants will have an outsized impact on giving trends.
Myth 3: Candid’s databases are updated once a year.
Even though the IRS only releases one 990 per organization per year, Candid’s data is “dynamic”: i.e., it is constantly being updated. Every day, more complete data sources replace partial sources, new transactions are added, data details are updated, and errors are corrected. Candid staff are continually cleaning data entries and adding or updating codes to improve accuracy, which affects how transactions are classified. Organizational-level details may also change as staff merge duplicate records and update contact details, mission statements, and coding.
Myth 4: Candid’s grants data set only includes grants from US foundations.
Years ago, this was true. However, in recent years, we’ve expanded to include grantmaking from public charities, and occasionally, from high-net-worth individuals (think MacKenzie Scott), corporations, and non-U.S. institutions. Additionally, although about 99% of Candid’s “transactions” data are traditional grants, we also capture information about a wide variety of transactions between donors and nonprofits, such as volunteer services, in-kind gifts, matching grants, and pledges.
Myth 5: Candid’s grants data is “plug and play.”
Candid’s data is widely considered the most comprehensive and detailed source of information about institutional grantmaking in the sector. However, that doesn’t mean that the data is ready as-is to answer every question about institutional giving. In fact, data comprehensiveness means that sometimes data needs to be removed to focus on certain topics. For example:
- To get more accurate numbers about foundation funding, other funder types should be excluded (e.g., corporate donations, public charities that give donations).
- To calculate dollars donated, pledges for future funds should be excluded.
- To look at change in grantmaking over time, multiple filters and cleaning steps need to be taken to distinguish between increase in giving and increase in data collection (or you can use the Foundation 1000 set).
To learn more about the details of Candid’s grants data, check out our recently released research manual.
About the author

Related posts

Community foundations: Donor-advised fund grants outpaced contributions in 2022
Find out how donor-advised fund grants given compared to DAF contributions among community foundations in 2022–and what research on this trend may mean for philanthropic giving in the future.
April 23, 2024

Co-leadership: A path to more diverse, sustainable nonprofits?
Dig into insights on nonprofit co-leadership to find out whether this commonplace trend of charitable organizations led by two leaders is opening the door to more overall diversity in the sector.
April 17, 2024

Youth community service: Belonging, reciprocity, and agency
Get insights into how young community service is being redefined by Gen Z and how young people are seeking to maximize their social impact—both for themselves and the communities they serve.
April 16, 2024

Connecting the dots: Fighting for equity through a data partnership
Elizabeth Barajas-Román of WFN shares what a demographic data partnership with Candid enables for advancing equity in the sector, including the first-ever, public dashboard to analyze intersectionality in nonprofit executive leadership.
April 11, 2024

The Maui wildfires: A record in disaster philanthropy, an opportunity to ‘get it right’
CEP’s Tanya Gulliver-Garcia explores funding for Maui wildfires—and what learnings the record-setting response to Hawaii’s recent natural hazard hold for future investment in disaster philanthropy.
April 9, 2024

Collecting demographic data: Nonprofits value transparency but need support
Viewpoint Consulting’s Kelly Brown shares new research findings on sharing demographic data via Candid, including the drivers and barriers of collecting this information to advance nonprofit transparency.
March 28, 2024
Kate, Digital Communications Manager, Candid says:
Yes, each bar represents a calendar year. The reason 2023 has so much less information is because the data is still being collected and we don't yet have Forms 990 data for that year. It usually takes 1-2 years to get complete data.
Wendy Talio says:
Just a question about the chart - does each bar represent a calendar year? I realize giving has been declining but the chart is showing a more dramatic message. Why are the number of transactions in 2023 so much less?
Tonya Hughes says:
Cathleen,
Thank you for the clarification. Funding throughout the year is dynamic, and it's promising that CANDID recognizes this and addresses the ebb and flow.
Ruth says:
Excellent information. Thank you