Pop the champagne: This year Candid’s grants data set turns 21!

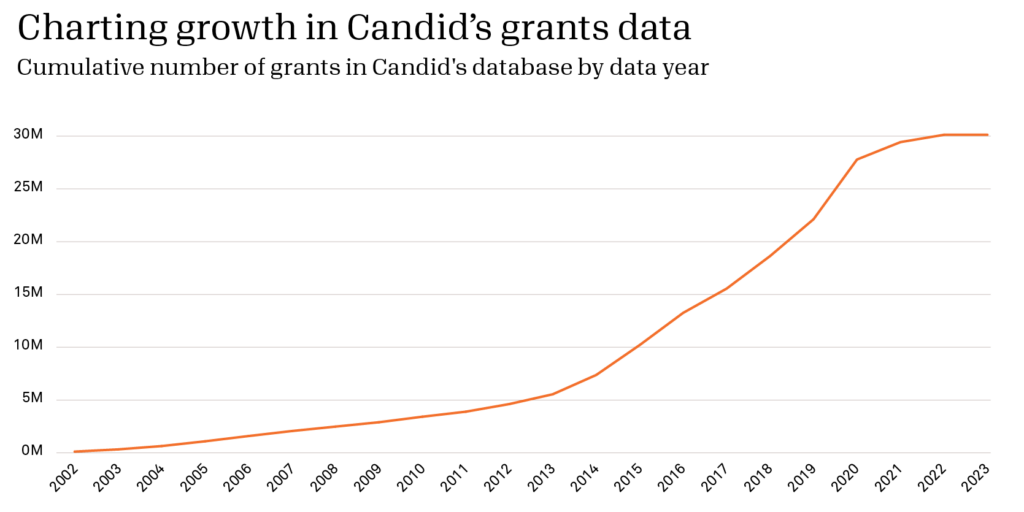
Candid’s grants data set currently includes comprehensive information about over 30 million grants and other philanthropic transactions, such as pledges, in-kind gifts, program-related investments, etc. This data powers tools like Candid’s Foundation Directory, allowing users to see who’s giving what, where, and to whom. Much like a developing human, our data collections have gotten bigger over time (see chart below), undergone developmental changes, and experienced the associated growing pains. And this year, it enters full-fledged adulthood!
To celebrate 21 yearsi of grantmaking data, we’re taking a look back at how far we’ve come and how we’ve evolved over the years. In this blog, we also share some insider tips on how to analyze this complex data set to gain accurate insights.
2002-2012 – Childhood
During the first 10 years, Candid staff primarily focused on collecting grants of $10,000 or more awarded by a sample of the largest U.S. private and community foundations. Data collection focused on the largest 800 funders nationally plus the top 25 grantmakers in each state and Washington, D.C., as measured by total giving. This typically resulted in about 900-1,300 funders represented and 100-150k grants collected in a given year. Staff entered, cleaned, and coded this data using largely manual processes.
2013-2014 – Tweens
A decade in, the importance of consistent year-over-year comparisons grew. So where once our annual data sets (which had been used to summarize yearly changes) contained a mix of fiscal years among foundations, they now would include the same fiscal year for all included organizations. And we would narrow the focus to 1,000 of the largest private and community foundations.
Analysis tip: We still create these annual data sets. Today, we refer to it as the “Foundation 1000”, and it is often used to look at historical grantmaking trends.
2015 – Teens
As Candid’s grants data approached its teenage years, many changes began to take place. We adopted more automation in the loading, cleaning, and coding of data. These new processes allowed for expanded data collection, including more grantmaking by smaller foundations, non-U.S. funders, and public foundations (aka grantmaking public charities).
These changes resulted in a substantial growth spurt, increasing our annual data collection from 900-1,300 funders and 100-150k transactions to over 100,000 funders and over 3 million transactions. Around this time, we also introduced the Philanthropy Classification System—a detailed coding system that provided more nuanced ways to explore this larger data set.
Analysis tip: The increased size of Candid’s grants data during the period from 2013-2015 shouldn’t be conflated with an increase in giving by donors. Researchers can use the Foundation 1000 or another cleaned subset of data to create historical trends for these years.
2016-2019 – Young adult
In 2016, we increased collection of federal grantmaking by U.S. government agenciesii. Before this time, government grants collection had been limited to a few agencies like the National Science Foundation and Department of Education. This change represented a large increase in the total number of dollars captured in Candid’s grants data set.
Analysis tip: Researchers will want to exclude federal grants if they are conducting analyses about foundation funding.
2020-present – Entering adulthood
As Candid’s grants data has come of age over the past few years, we’ve changed some of our data collection methods to adapt to changing realities. Specifically, in 2020, we ramped up efforts to identify, verify, and ingest very recent grants from news sources and other websites rather than simply waiting for the IRS to release Form 990 filings. We’ve also started capturing a new type of grantmaker: select, high-net-worth individuals (such as Mackenzie Scott).
The value of these efforts was supported by two concurrent—and connected—realities, which came to a head in 2020. These included the increasing unpredictability in receiving grants data from the IRS, as well as a surge in demand for very recent data on grantmaking in light of the COVID-19 pandemic and racial reckoning (a situation that we’ve termed the data/crisis catch-22).
During this time, we also introduced a new grant type called ‘pledges’ to coincide with a rising trend—funders making public promises (or pledges) to dedicate a certain (typically large) amount of resources to a given cause.
Analysis tip: As pledges are not the same as funds received, we recommend researchers analyze pledges separately from other types of transactions.
Over the past 21 years, we’ve strived to evolve Candid’s overall grants data set to reflect the needs of our ever-changing sector. It’s contributed to a broader picture of philanthropic giving by including more—and more recent and in-depth—data. However, we also know it can be difficult to track these changes and interpret data when methodologies are evolving and the scope is expanding.
As champions of data-driven transparency in philanthropy, we recognize that with great data comes great responsibility. Which is why we are releasing our new research manual. The manual is written for a research audience and offers all the detailed ins-and-outs of Candid’s grants and transactions data—where it comes from, how it’s changed, what to consider, and how to interpret it.
Still have questions about incorporating Candid’s data set into your research? Please reach out at [email protected].
i Foundation Center (one of Candid’s predecessor organizations), has been collecting data about philanthropic data far longer than 21 years, but the data sets commonly accessible and used—in products like Candid’s Foundation Directory and in our research initiatives—dates back to 2002.
ii Grantmaking by U.S. government agencies is sourced from usaspending.gov and was retroactively added to the data going back to 2014.
About the authors


Related posts

The 990s are here. Why that’s a big deal and what happens now
Discover how Candid responded to a million newly released 990s and what this fresh 990 data means for the social sector.
June 12, 2023

The data/crisis catch-22: How the pandemic created a social sector data gap
There’s a data/crisis catch-22: While it’s important to have recent data when managing a crisis, it’s also harder to get. Case in point: 990 data from the IRS.
September 26, 2022

Foundation giving and payout in 2022: What changed and what’s next?
Discover key insights into how foundation giving and payout changed last year and what these shifts may signal for 2023.
June 29, 2023

Drilling down on Candid’s commitment to data and transparency
Candid’s mission, to get you the information you need to do good, might seem simple, but it’s actually quite complex. Jake Garcia, Candid’s vice president of data, shares how we collect and organize data, and why we value transparency.
October 4, 2022

Money talks: Why tuning into the Giving Pledge matters
Discover why the Giving Pledge plays an influential role in shaping today’s philanthropic sector.
July 18, 2023

4 free ways to access Candid’s demographic data
Discover four free ways to access demographic data provided to Candid by over 55,000 nonprofits.
June 20, 2023
Lorent Damaseke Mvula says:
I appreciate for tha knowledge I have gained from this newsletter, how Candid Improves to better stand through data collection.