How does Candid collect data about grants?

In a recent article, the Chronicle of Philanthropy noted that the bulk of the recent (2020) racial equity grant dollars appears to have come from corporations. Candid’s data would suggest that is true. Our colleagues at the National Committee for Responsive Philanthropy criticized the article by highlighting the limitations of that conclusion: if companies are more likely to promote their gifts, Candid is more likely to capture them. They argued that the data we see in “real time” may not reflect a comprehensive picture of on-the-ground giving. Candid’s response? Both NCRP and the Chronicle are right.
Our database includes more than 17 million institutional grants going all the way back to 1956. So, how does Candid get funding data?
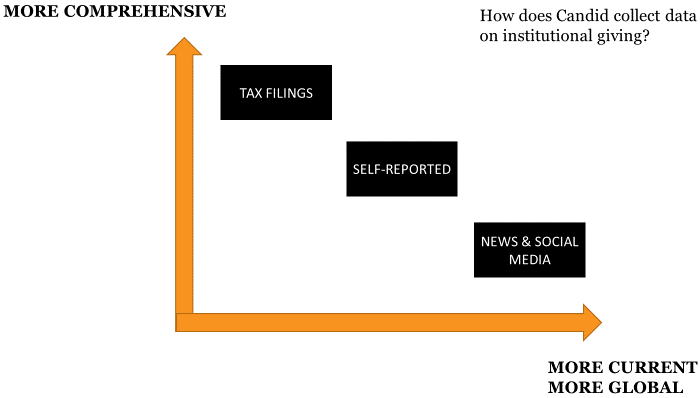
To oversimplify, Candid uses three mechanisms to collect grants data:
- First, Candid looks at tax filings by about 80,000 U.S.-based foundations which—by law—includes lists of grants made in the previous year.
- Second, we invite foundations around the world to proactively share self-reported grants data through our e-reporting program. More than 1000 foundations—including many of the world’s largest—provide this data on a regular basis.
- In the last year, we’ve added a third mechanism. Each night our systems “read” about 300,000 media articles and scan social media. From that, we identify about 1,000 pieces of news about the social sector, including many grants.
In each of the three cases, we use machine learning algorithms to code grants by subject, strategy, population, and more. We integrate these three different streams of information into a single database that then feeds our tools and research.
Each of these three sources of data has strengths and weaknesses. The tax filings offer a remarkably comprehensive view of grants in the United States. By its very nature, however, tax filing data tends to be at least a year and half old.
Many foundations recognize that transparency can reduce barriers, increase efficiency, and enable learning across the field. Self-reported data is not comprehensive, however. The foundations that share data directly with Candid represent the bulk of institutional giving in the United States, but not the bulk of institutional givers. And while many foundations outside the United States self-report data, they tend to be concentrated in wealthier regions of the world (notably Europe and China).
Our newest mechanism—news scraping—is lightning-quick and far more global. But it has its own limitations. It is more likely to capture gifts that are promoted. A silent, anonymous gift will go unnoticed by our algorithms. And, while it is a global mechanism, we recognize the limitations—especially around language—of our approach outside of the United States.
We believe that our three-part approach is the best available way to track institutional giving. But its limitations can lead to uncertainty and disagreement, such as the one NCRP voiced in response to the Chronicle article.
Arguments like this will continue. And they should. Our field needs the best available data, and we also need an ongoing debate about what that data means.
About the author

Related posts

What do we know about nonprofit leaders and staff with disabilities?
Explore insights about nonprofit staff and board members with disabilities, such as their underrepresentation across the sector and the barriers they face in leadership roles.
July 22, 2024

5 takeaways on trust in NGOs to manage new innovations and technologies
Dig into data-driven trends on the public’s trust in NGOs, business, government, and media to discover what inspires confidence in these institutions based on Edelman’s 2024 research.
July 17, 2024

Toward nimble and creative funding for LGBTQ communities through a time of crisis
Discover recent trends in funding for LGBTQ communities and causes—and why more philanthropic support is needed—based on the Funders for LGBTQ Issues 2024 Resource Tracking Report.
July 10, 2024

What do we know about LGBTQIA+ nonprofit leaders and staff?
Delve into data-driven insights on LGBTQIA+ nonprofit leaders and staffs’ representation and real-world experiences in the sector, including why more support for their community is critical.
June 25, 2024

Foundation giving remained steady in 2023. What’s the outlook for 2024?
What could foundation giving in 2023 mean for giving to nonprofits this year? Find out by delving into Candid’s analysis of last year’s foundation giving and payout data, including what changes to expect in grantmaking in 2024.
June 12, 2024

Did nonprofit leadership become more racially diverse after 2020?
Is nonprofit leadership more racially diverse than in 2020? Find out by exploring insights derived from demographic data that help explain what recent shifts in nonprofits led by BIPOC CEOs may signal.
May 2, 2024